실제 고객들은 무엇을 중요하게 볼까?
술고라는 서비스는 우리가 하고 싶어서 만들었지만, 그럼에도 가장 중요한 건 결국 고객의 니즈라고 생각한다. 디자인을 배우고 상업예술에서 잠시 일을 했었던 나는 예술과 비즈니스를 가르는 중요한 기준 중에 하나가 바로 이 ‘제작자와 구매자 간 니즈의 일치’라고 생각한다.
고객의 생각이나 니즈와는 무관하게 만들고 싶은 것을 만든다면 그것은 ‘예술’, 구매자가 원하는 것이 무엇인지 파악하고 이를 만족시켜주기위해 만드는 것은 ‘비즈니스’의 영역이라고 생각한다. 물론 이 둘은 함께 공존할 수 있고, 이 둘이 교집합을 이루는 순간을 '덕업 일치'라고 생각한다.
서론이 길었는데 본론으로 들어가자면, 우리는 우리끼리만 만족하기 보다는 고객의 니즈를 확인하고 고객의 만족도를 높여주고 싶었다. 그래서 술 취향 항목별로 중요도에 대한 구글 설문을 돌리기로 하였다. 고객들이 무엇을 중요시 여기는지 알 수 있다면 더 고객 친화적인 알고리즘을 짤 수 있을 것 같았다.
이 설문에 무려 65명이나 참여해주었다ㅜㅜ (도와준 26기 찬규 님, 28기 찬주님 감사합니다.)
실제 설문을 해보니 의외로 'mbti'나 '기술스택'은 술친구를 만드는데 상관이 없다는 반응이 나왔다. mbti가 중요할 것이라고 생각했던 우리의 생각과는 사뭇 달라 놀랐다. 그리고 우리가 놓치고 있었던 부분들도 지적해주어 우리 서비스에 대해 다시 생각해보는 계기도 되었다.


이런 피드백들은 우리 서비스의 본질을 생각해보게 만든다는 점에서 매우 소중한 피드백이라는 생각이 들었다. 피드백을 반영하여 더 많은 고객들을 만족시켜줄 수 있다면 이는 천금 같은 피드백이 아닐까?
술고리즘 : 술 취향 매칭 알고리즘
요즘에는 알고리즘이 없는 서비스가 드물 정도로 맞춤형 서비스들이 많다. 유튜브만 해도 내 취향을 정확히 알고 영상을 추천해주지 않던가? 나는 이런 알고리즘에 대해서 막연한 동경을 가지고 있었고 개발자가 되면 꼭 만들어보고 싶다는 생각을 했었다. 1차 프로젝트 때에는 그럴 기회가 없었지만 이번 술고 프로젝트에서는 매칭 시스템이 있었기에 이를 알고리즘으로 꼭 구현해보고 싶었다.
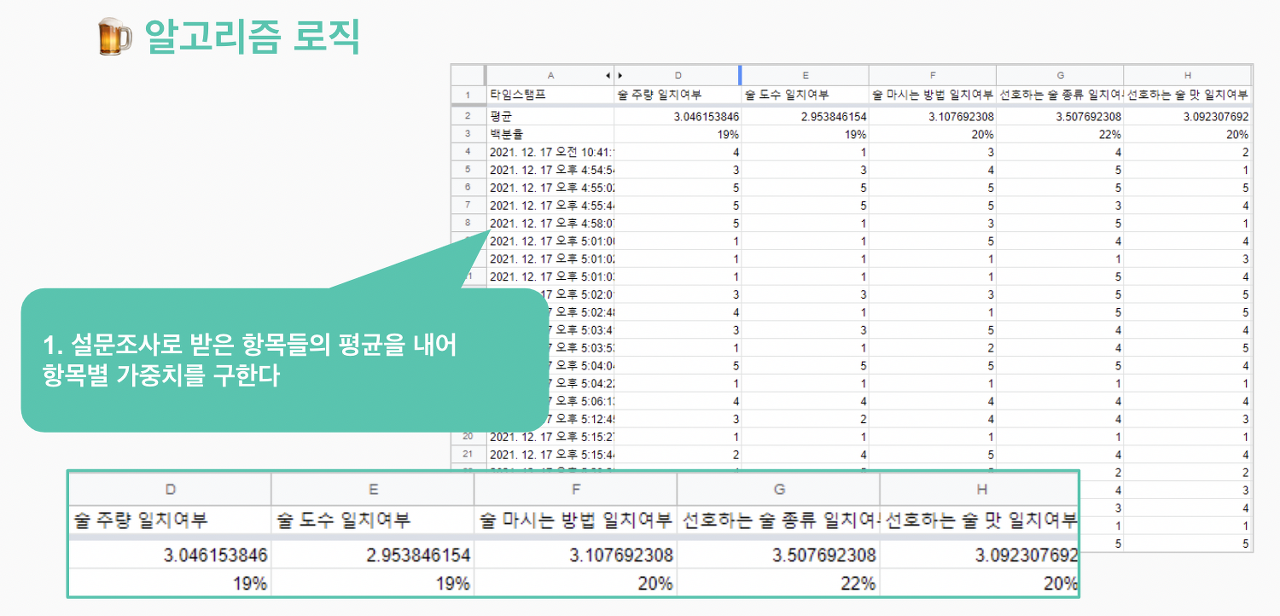
먼저 매칭 알고리즘을 만들기 위해 어떤 데이터가 필요한지를 떠올려 보았다. 앞선 설문조사를 통해 고객들이 어떤 술 취향을 중요시 여기는지에 대한 데이터는 가지고 있었다. 그리고 실제 사이트에 가입한 회원들은 가입 시 서베이 작성을 통해 개인들의 술 취향을 데이터로 저장하게 된다.
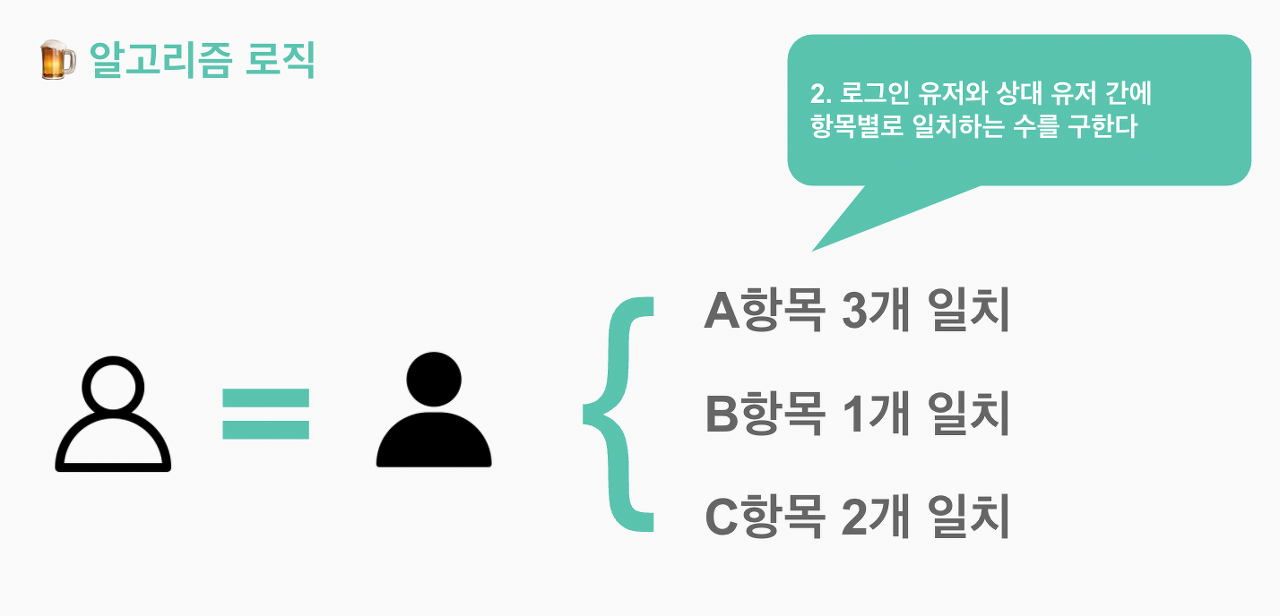
우리는 이러한 데이터를 가지고 로그인한 유저와 다른 나머지 유저들간에 항목별 일치 여부를 확인하고, 앞서 설문을 통해 얻은 중요도를 항목별 가중치로 만들어 항목별 점수를 계산, 최종 합계가 가장 높은 상대를 유저에게 매칭 시켜주도록 하였다.
이 로직을 이미지로 쉽게 풀어보자면 다음과 같다.

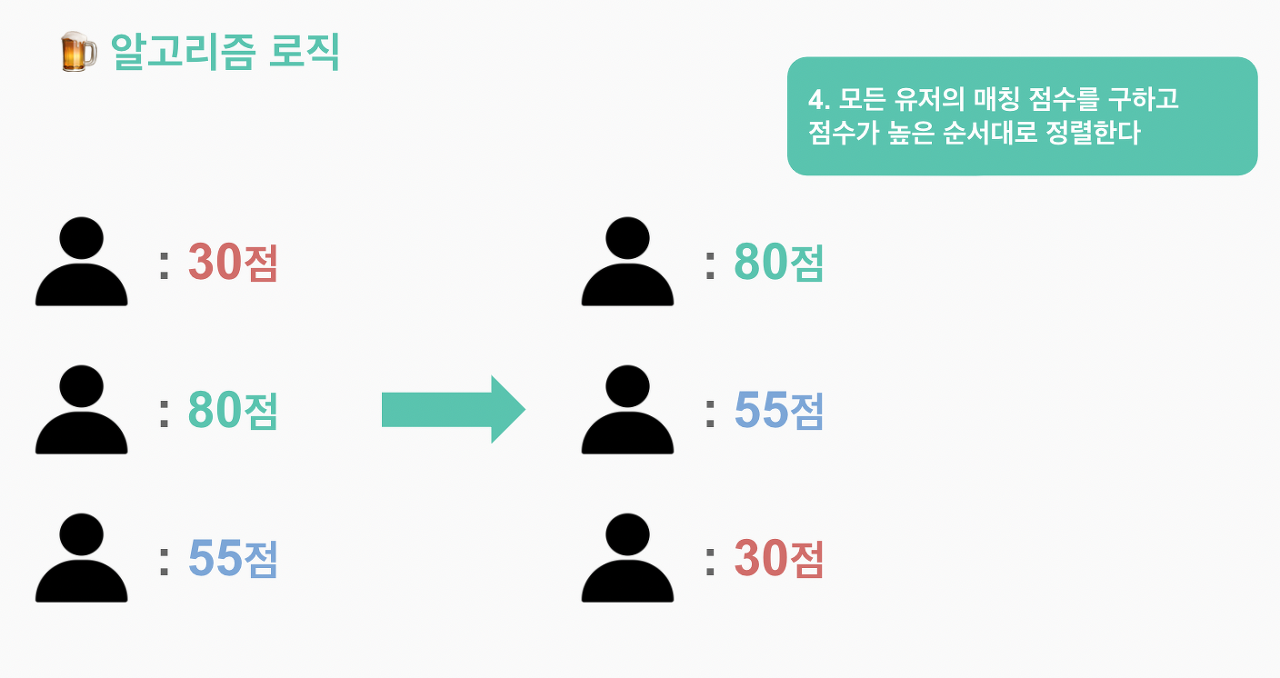
최종적으로 이 알고리즘을 이용하면 나와 상대 유저들에 대한 매칭 점수를 모두 계산하고 가장 높은 순으로 9명을 내게 보여준다. 나는 매칭 된 리스트를 보면서 직접 만나고 싶은 사람을 선택할 수 있다.
그런데, 이 알고리즘에는 치명적인 문제점이 있었다.
98% 부족한 알고리즘
우리가 알고리즘을 만든 이유는 고객에게 딱 맞는 상대를 추천해주기 위함이었다. 하지만 직접 설문조사를 하고 실제 코드로 구현하면서 한 가지 의문이 들었다. 이게 정말 개인 맞춤형이 맞을까?
겉으로 보기에는 자신과 일치하는 항목들에 대해 점수를 매기고 반환해준다는 점에서 개인 맞춤형으로 볼 수 있었다. 하지만 이는 너무 1차원적이라는 생각이 들었다. 가장 큰 문제는 항목별 가중치가 사람들의 평균 데이터에 근거하고 있다는 점이다. 평균이라는 것은 언뜻 대중을 대변해주는 듯하지만, 이는 다시 말해 개인적이지 않다는 의미이기도 하기 때문이다.
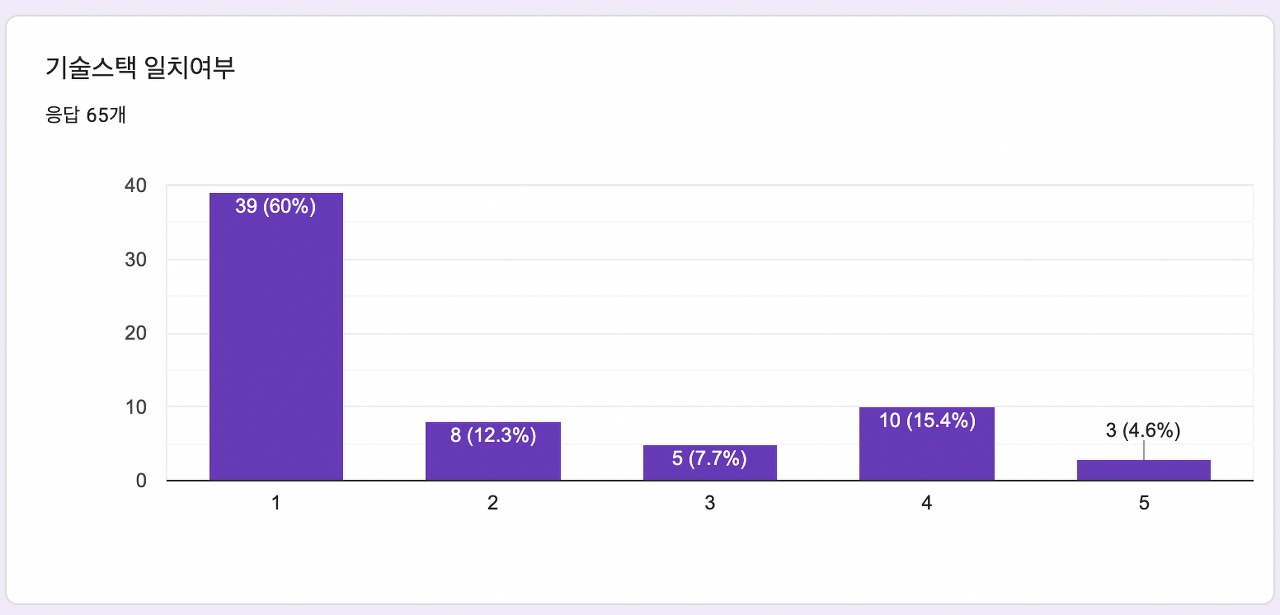
'기술 스택' 항목의 경우를 예로 들어보겠다. 응답자 평균으로 볼 때 현재의 알고리즘은 기술 스택의 중요도를 평균 ‘2’로 보고 점수를 매긴다. 하지만 실제 다수의 응답자들의 기술 스택 중요도는 ‘1’이다. 또한 반대로 기술 스택이 매우 중요하다고 답한 3명은 자신의 취향과는 전혀 다른 엉뚱한 사람들과 매칭 된다. 즉 이 알고리즘은 개인 맞춤형이라고 말할 수 없는 것이다..
문제점은 이 뿐만이 아니다. 항목별 일치하는 수에 따라 점수가 높아지다 보니, 중복 선택 항목을 많이 선택한 사람은 그 누구와도 높은 점수가 나오는 문제가 생겼다. 즉, 중복 선택 항목을 모두 선택하기만 하면 술 취향 매칭 시 최상단에 올라가게 되는 것이다.
그래서 앞으로
이러한 문제들을 해결하기 위해서는 먼저 개인별로 어떤 항목을 중요시 여기는지에 대한 구체적인 취향 데이터를 따로 수집할 필요가 있다. 이를 활용하면 알고리즘에 적용되는 항목별 가중치도 평균이 아니라 모두 개인화시켜 더 정교한 알고리즘 구현이 가능할 것이다.
이 개선안은 이번 스프린트 진행 상 반영할 수는 없었지만 추후 리펙토링 과정에서 구현하기로 팀원들과 합의하였다. 이번 실수를 통해 매칭 서비스와 알고리즘의 목적이 무엇인지 다시금 생각해보는 소중한 경험을 얻었다.
'나는 이렇게 논다 > Suulgo_# 술취향 매칭' 카테고리의 다른 글
| #7_술GO? 하기 전에 회GO! (0) | 2022.01.22 |
|---|---|
| #6_코드말고 술잔 부딪치시는 건 어떠세요 ? (0) | 2022.01.22 |
| #4_난 당신의 술 취향을 알고 있다. (0) | 2022.01.22 |
| #3_Faker만 있으면 DB업로드가 두렵지 않아 (0) | 2022.01.22 |
| #2_모델링 이렇게 해도 되나? (0) | 2022.01.22 |

